What Is Natural Language Processing (NLP) and What Does It Mean for SEO?


Natural language processing (NLP) has become a common SEO buzzword.
At the recent Chiang Mai SEO conference (CMSEO), NLP was mentioned in almost half of the presentations.
But just because NLP has become prevalent in SEO-speak doesn’t mean it’s well understood.
That’s because NLP is really, really, complicated.
What is natural language, anyways?
Natural language is any language humans speak that’s developed naturally in use.
So what is natural language processing?
At its core, NLP attempts to solve one of the oldest, thorniest — and most ambitious — of all computing problems:
Can we program machines to understand what we say or write in natural language?
And can we teach them to talk back?
Natural Language Processing vs. Neuro-Linguistic Programming
Ever googled “NLP?”
You may well have been confused by the results.
That’s because natural language processing shares an acronym with neuro-linguistic programming.
Neuro-linguistic programming is a largely discredited, pseudoscientific approach to psychotherapy and behavior modification.
First devised in the 1970s, neuro-linguistic programming became popular in self-help and life-coaching circles.
 Tony Robbins, Early Advocate of Neuro-Linguistic Programming (Source: Product Hunt)
Tony Robbins, Early Advocate of Neuro-Linguistic Programming (Source: Product Hunt)
Before being sued by one of its originators, Richard Bandler, motivational guru Tony Robbins was a strong proponent of neuro-linguistic processing and helped popularize its techniques.
Celebrities like Bill Gates, Oprah Winfrey, and Tiger Woods have all apparently benefited from neuro-linguistic programming techniques.
So, perhaps it’s no wonder that neuro-linguistic programming is the better-known of the two NLPs vs. natural language processing.
From here on out, we’ll leave neuro-linguistic programming to the life-coaches.
For the remainder of this post, NLP refers exclusively to natural language processing.
The History of NLP
The roots of NLP date back to the dawn of modern computing.
 Alan Turing (Source: University of Cambridge)
Alan Turing (Source: University of Cambridge)
In 1950, famed codebreaker and computer scientist, Alan Turing (portrayed by Benedict Cumberbatch in the Oscar-winning film, The Imitation Game), wrote a foundational paper entitled “Computing Machinery and Intelligence.”
Turing’s first sentence poses a seminal question that computer scientists and philosophers, AI engineers and science fiction authors, still wrestle with today.
“Can machines think?”
Turing’s genius may have been underestimated during his short, tragic life, but 70 years later, we’re still looking for an answer to that fundamental question.
From the beginning, NLP has played a pivotal role in the potential solution.
Initially, many scientists thought teaching a machine to read or speak would be relatively easy.
There were promising early successes.
The Georgetown-IBM Experiment in 1954 demonstrated some success in translating Russian sentences into English — albeit with a small sample size of only 250 words and six grammar rules.
But the end goal of programming a computer to understand language — and convincingly generate it — remains elusive.
 In 1964, the US government commissioned the Automatic Language Processing Advisory Committee.
In 1964, the US government commissioned the Automatic Language Processing Advisory Committee.
Two years later, in 1966, ALPAC gave a withering assessment of the progress made up to that point in NLP and automated language translation in particular.
As a result, government funding into NLP research largely dried up for nearly two decades.
1966 also saw the debut of the first chatterbot — or chatbot as they’re now known.
ELIZA, created by Joseph Weizenbaum of MIT, was designed to emulate a human psychotherapist.
Essentially, ELIZA would parse the input “she” was given, then rephrase and reflect it back to the user as a question.
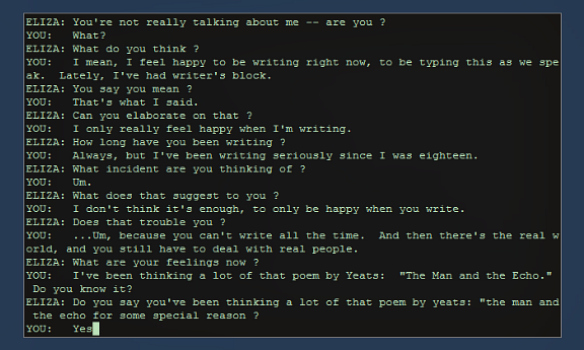 A Chat with ELIZA (Source: Thought Catalog)
A Chat with ELIZA (Source: Thought Catalog)
Despite ELIZA’s obvious limitations, many users were convinced “she” exhibited human understanding and compassion.
Weizenbaum, ELIZA’s creator, had considerable misgivings about this, saying, “I had not realized … that extremely short exposures to a relatively simple computer program could induce powerful delusional thinking in quite normal people.”
ELIZA was merely the first in a long line of chatterbots, many of which helped propel the study of NLP forward.
Some other notable chatterbots include PARRY (who had a memorable conversation with ELIZA in 1972), Jabberwacky, A.L.I.C.E., and SHRDLU.
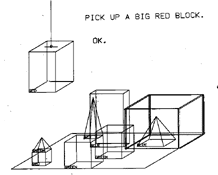 SHRDLU’s Original Screen Display (Source: Stanford)
SHRDLU’s Original Screen Display (Source: Stanford)
Developed in the late 1960s and early 1970s, SHRDLU was designed by Terry Winograd at MIT.
SHRDLU was one of the earliest successful attempts at programming a computer to understand natural language.
As Winograd put it, “[SHRDLU] answers questions, executes commands, and accepts information in an interactive English dialog… The system contains a parser, a recognition of English grammar, programs for semantic analysis, and a general problem-solving system… It can remember and discuss its plans and actions as well as carrying them out.”
Winograd’s work on SHRDLU led to his publication of Understanding Natural Language in 1972.
Research into NLP picked up steam again in the 1980s.
Scientists and engineers began to focus on pure statistical methods of interpreting and generating language.
This was a significant departure from earlier experiments that relied heavily on sets of handwritten rules.
Machine learning also became an integral part of NLP and remains so to this day.
In 1994, IBM launched Simon, the world’s first smartphone.
 Simon — The First Smartphone (Source: Gadgets360)
Simon — The First Smartphone (Source: Gadgets360)
Featuring a touchscreen and rudimentary predictive text, Simon paved the way for the next generation of smartphones — like the iPhone — which brought NLP technology to a much wider audience.
1997 saw the discovery of long short-term memory (LSTM) networks. LSTM has proven indispensable in speech and handwriting recognition applications.
Early in the 2000s, Yoshio Bengio created the first neural language model.
This helped lead to the discovery of feed-forward and Recurrent Neural Networks (RNN) — both crucial developments for NLP.
To say Bengio’s work has been influential is an understatement. He is the most-cited deep learning expert in the world, averaging 131 citations a day.
The 2000s also saw exponential growth in processing capability for machine learning — as well the number and size of available data sets.
In 2011, NLP technology took a massive leap into the mainstream with Apple’s introduction of Siri as part of iOS with the launch of the iPhone 4S.
Siri blazed a trail for other virtual assistants like Alexa and Google Home.
All of these are examples of how NLP technology is transforming the way we live today.
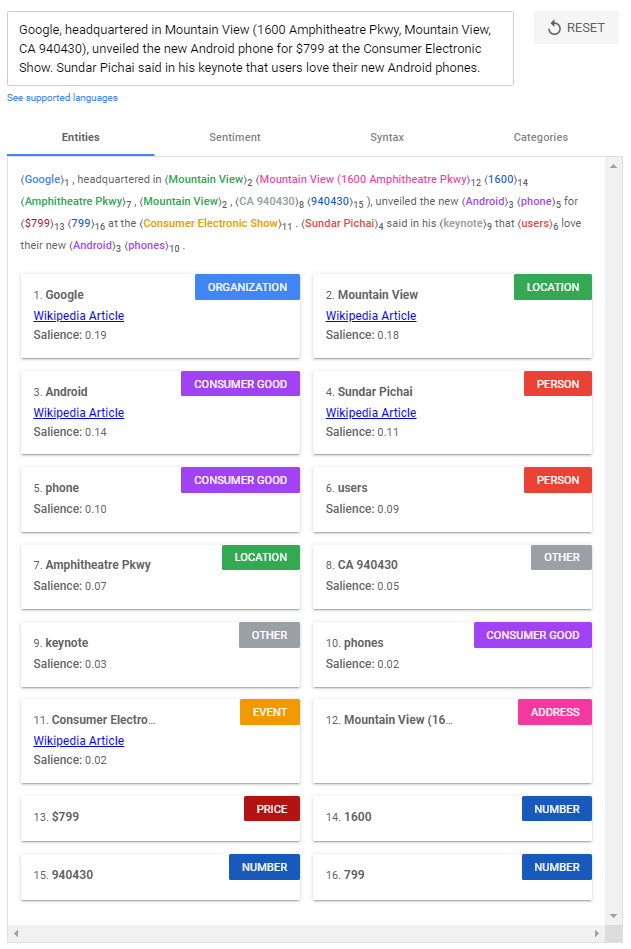
What Is the Google Natural Language API?
In 2016, Google launched its Natural Language API as part of its Google Cloud offering — making Google-powered sentiment analysis, entity recognition, content classification, and syntax analysis available to third-party developers for the first time.
Google Natural Language (NL) and its sister product, Cloud AutoML, gives developers with no NLP or machine learning expertise access to NLP models “pre-trained” by Google using vast data sets.
The primary target customer for Google NL is a developer or business who wants to process a large amount of unstructured data and turn it into structured data.
One use case could be a company with a large number of paper records containing valuable customer data — such as invoices.
Using another Google Cloud product, Optical Character Recognition (OCR) — part of the Google Vision API —the printed invoices can be scanned in bulk and converted into unstructured data.
This unstructured data can then be analyzed by Google NL or Cloud AutoML and turned into structured data — for example, with fields such as name, address, phone number, email, etc.
Google NL features the following tools:
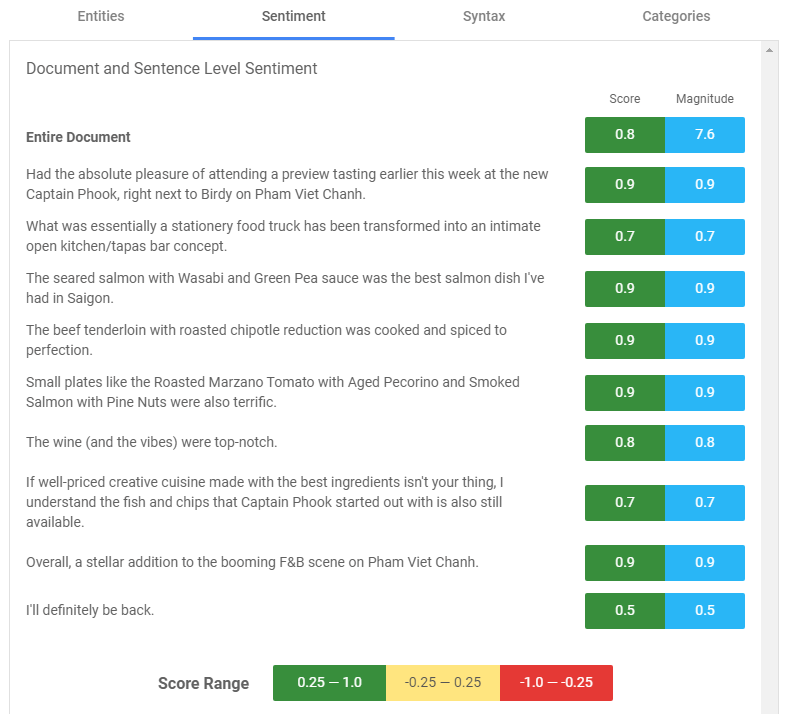 A Strongly Positive Restaurant Review Analyzed by Google NL
A Strongly Positive Restaurant Review Analyzed by Google NL
Sentiment Analysis
Google NL can analyze text and reliably determine whether the emotional attitude of the writer was positive, neutral, or negative.
According to Google Natural Language Product Manager, Sudheera Vanguri, sentiment analysis allows developers to “determine the prevailing emotion of a writer within a text passage, both in conversations as well as documents.”
Google NL measures sentiment analysis on a scale of 1.0 to -1.0 — with 1 being the most positive, 0.25 to -0.25 being neutral, and -.025 to -1.0 being negative.
The other variable is magnitude, which indicates how strongly the emotional opinion of the text is expressed.
From a tweet to a tome, sentiment analysis can judge whether the writer’s tone is positive, negative, or indifferent.
Application
Sentiment analysis can be particularly useful for social media monitoring and customer experience management.
For large businesses with thousands of online reviews and hundreds of thousands of social media comments related to their brand, the ability to analyze sentiment at scale with little to no human supervision can be a powerful tool.
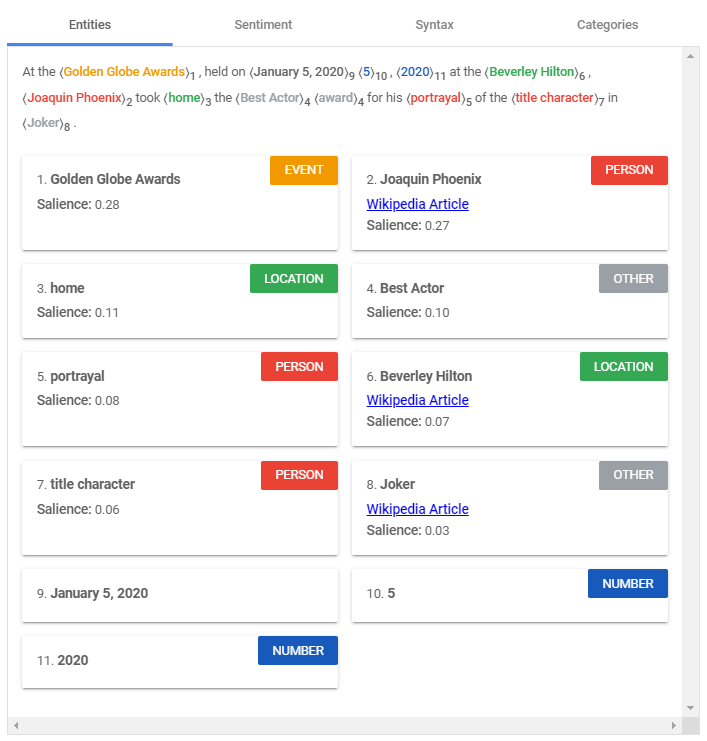
Entity Analysis
Google NL’s entity analysis feature parses text and attempts to identify “named ‘things’ such as famous individuals, landmarks, common objects, etc.”
Wherever possible, Google also returns the relevant Wikipedia link — or Google Maps link in the case of locations.
Entity analysis results are ranked — from high to low — by salience score.
According to Google’s documentation, “salience indicates the importance or relevance of this entity to the entire document text.”
So, using the example above, Golden Globes, as an entity, is slightly more salient to the overall text than Joaquin Phoenix — and much more important than the name of the film he won the award for.
Note that the combined salience scores always add up to 1.00.
Besides celebrities and landmarks, entity analysis also attempts to identify other named things and classify them as entities under such categories as event, consumer product, date, address, work of art, etc.
Application
News organizations generate vast amounts of content every day.
Entity analysis can identify the people, places, companies, and other entities mentioned in each article to help classify and categorize the content.
This can help ensure accurate and fluid content retrieval.

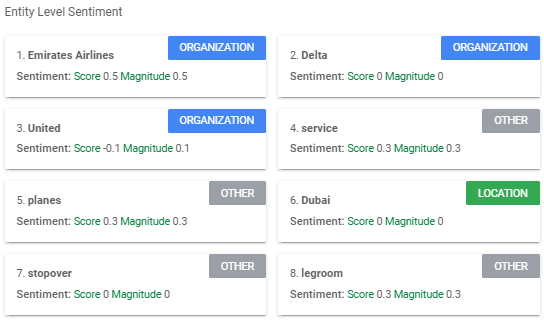
Entity Sentiment Analysis
A granular approach combining entity and sentiment analysis, entity sentiment analysis, “attempts to determine the sentiment (positive or negative) expressed about entities within the text.”
As you can see from the above example, NL correctly identifies that the sentiment for Emirates Airlines is strongly positive, while for United Airlines, it’s negative.
It’s not foolproof, though — as you can see NL didn’t detect a negative sentiment for Delta.
Like every other aspect of NLP, its accuracy is expected to improve over time.
Application
Businesses could use entity sentiment analysis to help determine whether mentions of their brand are positive or negative in large batches of content.
For example, if a business wanted to categorize brand mentions on a popular review site like Yelp as positive or negative, a combination of sentiment analysis and entity sentiment analysis could help turn the bulk unstructured data into structured data.
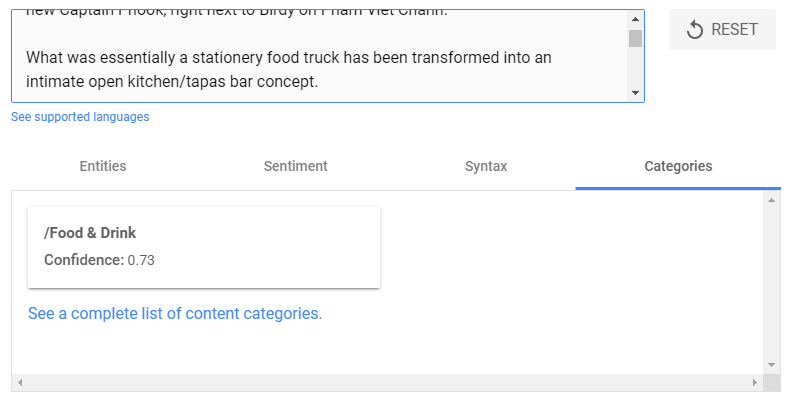
Content Classification
A simple (for NLP) feature of Google NL is its ability to categorize content.
After analyzing the text, Google NL attempts to determine which of over 700 categories (and subcategories) — from Arts and Leisure to Travel — it should classify the content under.
NL also gives you a confidence score by percentage — 73%, for the example above.
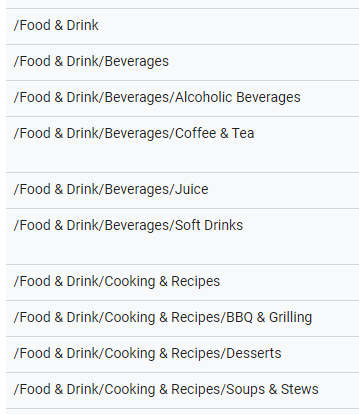
As you can see from the above example, the categories follow a familiar hierarchical structure, and the subcategories get quite granular.
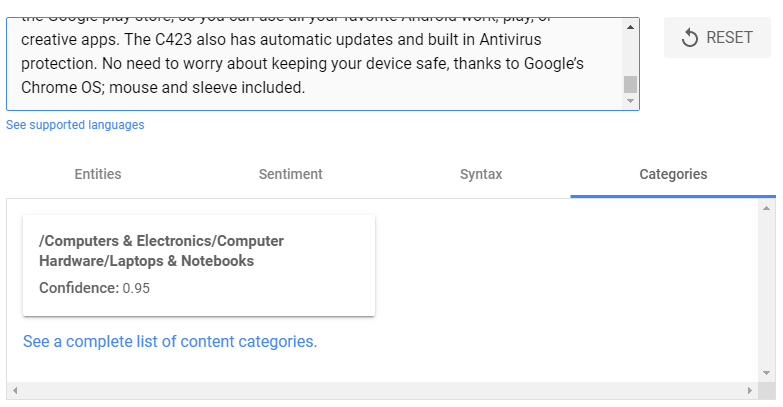
When I entered a snippet of a review for a new ASUS Chromebook, NL was much more confident categorizing — and then subcategorizing — the content then it was with the restaurant review.
Application
Perhaps the most intuitive and straightforward of all the Google NL functions, content classification is nonetheless an extremely powerful method of scaling the categorization of large amounts of content.
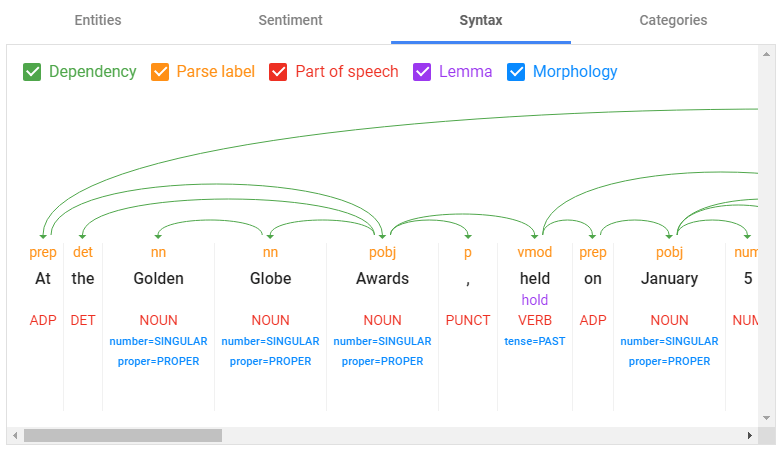
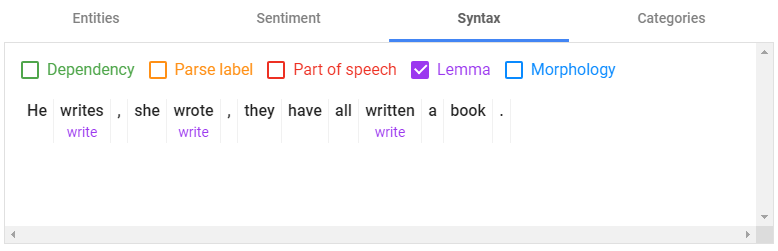
Syntactic Analysis
While the other out-of-the-box features of Google Natural Language are relatively intuitive and don’t require a machine learning or linguistics background, that’s not the case for syntactic analysis.
Syntactic analysis parses text and breaks down its syntax into its constituent parts — known as sentences and tokens.
Tokens are the “smallest syntactic building blocks of text.”
In natural language, tokens are usually words but can also be punctuation marks or numbers.
Google NL can analyze the syntax of 11 different languages, including Chinese, Korean, and Russian.
As you can see from the above example, syntactic analysis goes far deeper than just splitting text into sentences and tokens.
It also displays the morphology of each token and the syntactic dependency between tokens and sentences.
In linguistics, morphology is the study of the internal structure of words.
Syntactic analysis offers a fascinating window into how Google NL sees and interprets language at a granular level.
It is also highly technical and likely of more than passing interest to only a very select audience.
If you want to learn more about syntactic analysis, what follows are short definitions of each category NL examines, as well as resources to read further.

Dependency Parsing and Dependency Trees
A crucial element of computational linguistics and NLP, dependency parsing attempts to reduce natural language its smallest components — and determine the relationship of these tokens to each other within a sentence.
Dependency parsing labels each token with one of 37 universal syntactic relation tags (shown in orange in the example above).
A dependency tree (shown in green) is a graphic representation of the relationship between tokens in a sentence.
In natural language, meaning isn’t only derived from the definition of individual words in a sentence but also how the words relate to each other.
Dependency parsing attempts to reduce these relationships into a form that machines can understand.
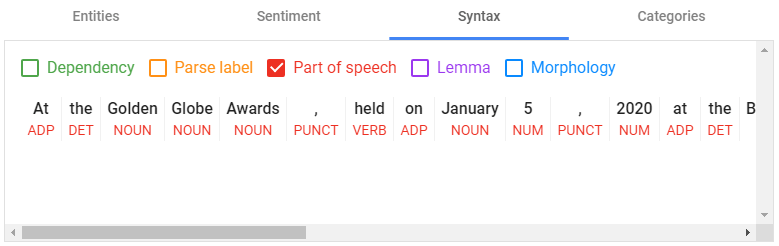
Part of Speech
Shown above in red, part-of-speech tagging (POS) likely looks less intimidating than dependency parsing to anyone who remembers their grammar lessons.
Appearances can be deceiving.
Part-of-speech tagging doesn’t just seek to identify whether tokens (words/punctuation/numbers) are nouns, verbs, or determiners, etc., but also to determine meaning — and often pronunciation — based on context.
One relatively simple, but common, problem POS tagging can solve involves heteronyms.
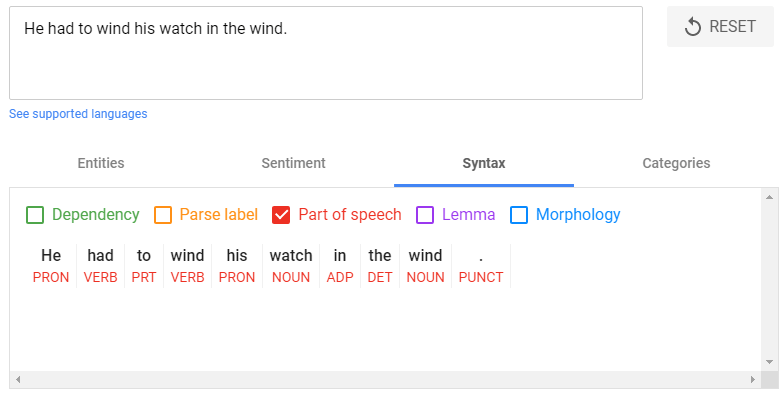
Common in English, heteronyms are words spelled the same but with different meanings and pronunciations based on context — often depending on whether they’re verbs or nouns.
In the above example, the word “wind” has a different meaning and pronunciation dependent on its relationship to the other words in the sentence.
The words around wind help determine if it’s a verb ( \ ˈwīnd \ ) or a noun ( \ ˈwind \ ).
Of course, for POS tagging to be effective, it must solve far more complex problems — and go far deeper than nouns and verbs.
 Universal Part of Speech Categories (Source: Github)
Universal Part of Speech Categories (Source: Github)
Just to give you an idea, English has 12 categories — such as adjectives, nouns, verbs, punctuation, etc. — and 45 tags, which are essentially subcategories.
For example, there are four different tags for nouns and seven tags for verbs.
POS tagging seeks to be universal — so it’s not just English that has 12 categories.
 (Source: LREC Conference)
(Source: LREC Conference)
One set of categories applies to all human languages.
Though as you can see from the above chart, not all categories and all tags apply to all languages.
Chinese, for example, has 294 tags — while Dutch has only 11.
Application
POS tagging has many critical applications in NLP, particularly in machine translation (think Google Translate) and speech generation and recognition (think Google Home).
Slav Petrov and Ryan McDonald of Google helped develop the universal part-of-speech tagset used in Google Natural Language and many other applications.
Lemma
Lemma finds the root of different tenses and variations of words.
In the example above
Another way of looking at it is that the lemma is the “head word” in a dictionary entry — all of the variations such as wrote, written, and writing derive from the root word, write.
 (Source: Merriam Webster)
(Source: Merriam Webster)
Application
Finding the lemma of words in a body of text is known as lemmatization and can help prepare text for further processing.
The programming language, Python, for example, uses lemmatization extensively.
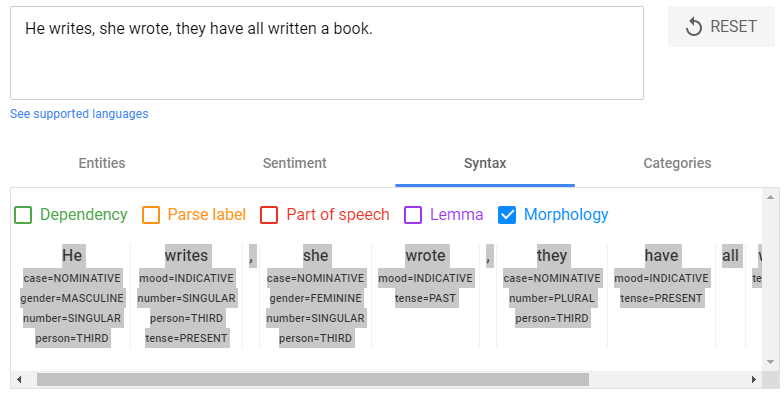
Morphology
The morphology function yields yet more information about the individual words in text, such as word tense, point of view, and modality.
 (Source: Apple)
(Source: Apple)
NLP In Action
Whether you realize it or not, you probably engage with NLP-powered technology each and every day.
Here are just a few examples of NLP at work:
- Autocomplete in Google Search and Gmail
- Siri, Alexa, and Google Home devices
- Chatbots
- Language translation software
- Predictive text
- Spam filters
- Spell and grammar check
- Search
What Does NLP Mean for SEO in 2020 and Beyond?
In late October 2019, Google announced “the biggest leap forward [in Search] in the past five years, and one of the biggest leaps forward in the history of Search.”
Christened BERT (Bidirectional Encoder Representations from Transformers), the update primarily focused on using NLP to better understand longer, more conversational search queries — and the user intent behind them.
BERT “process[es] words in relation to all the other words in a sentence, rather than one-by-one in order.”
It considers “the full context of a word by looking at the words that come before and after it—particularly useful for understanding the intent behind search queries.”
BERT signals a shift away by Google from dependence on traditional keyword-based search.
Google estimates that BERT will impact approximately 10% of search queries and signaled that NLP would play an even more significant role in the future.
BERT isn’t just the name of a search algorithm update.
It’s an NLP technology that Google developed and made open source in late 2018 and is widely considered a game-changer in the field.
Is NLP currently a factor in SEO?
“It’s hard to formulate a definite theory about that. NLP is a broad concept which helps the algorithm to understand people better.
After all, both spoken and written language has a lot of quirks, exceptions, and ambiguity. And NLP helps to determine not only the context of each word and phrase but the sentiment as well.
NLP is one of many algorithms incorporated into Google’s rank brain. There are direct and indirect signals that help to arrange the SERP’s order and select direct answer boxes.
Using proper entities related to the targeted niche, and putting them into the right context helps to fulfill the algorithm’s requirement regarding the comprehensiveness and complexity of the content.
Adjusting the overtone to the sentiment analysis supports user’s intent.”
SLAWEK CZAJKOWSKI — SURFER
Search Engine Journal’s Roger Montti sees Google’s increased use of NLP “as an opportunity to bring more traffic with content that is more focused and well organized.”
Search engine algorithm expert Dawn Anderson said BERT “won’t help websites that are poorly written.”
IS GOOGLE’S NATURAL LANGUAGE API A RANKING FACTOR?
“I’ve run some tests on the entities produced by Google’s NLP API.
In a test environment, by simply putting entities on a page, I cannot get rank improvement, and I struggle to get an adjustment in the NLP content categories.
That said, in the wild, I believe that I’ve seen faster indexing and faster rank improvement of pages by adding entities to those pages as part of my optimization strategy.
For the time being, I’m using the NLP API as a sanity check on the optimization that I am doing and sprinkling in entities that I may have missed through my normal optimization process.”
KYLE ROOF — PAGEOPTIMIZERPRO
In a Search Engine Journal webinar, Dawn Anderson was asked if you can optimize your content for BERT and NLP.
“Probably not… You’re better off just writing natural in the first place.”
That may mean focusing less on such time-honored SEO metrics as keyword density.
“Keyword density will even be less important in the future as Google better understands the context of the content you are writing,” said Neil Patel of Ubersuggest.
Will NLP play a bigger role in SEO in the future?
Even though Google’s NLP is quite reliable in terms of English content, it’s unusable with other languages.
We have to be aware that NLP’s development is still a work-in-progress.
I’m sure that NLP will play a more significant role in the future, and our duty, as SEO specialists, is to learn how to utilize it properly.
Surfer has just released an NLP Analysis feature with Sentiment Analysis, Entities Coverage, and Context Usage.
Initial results shown by Surfer clients using NLP analysis have been very encouraging.
The subject is more urgent for those who offer services in English speaking markets.
For others, it’s a big chance to get ahead and prepare for further Google updates.
SLAWEK CZAJKOWSKI — SURFER
Danny Sullivan, co-founder of Search Engine Land and now Google’s public Search Liaison, attempted to end speculation about optimizing for BERT and NLP, tweeting, “There’s nothing to optimize for BERT, nor anything for anyone to be rethinking. The fundamentals of us seeking to reward great content remain unchanged.”
So what does NLP mean for SEO?
As Google becomes ever better at understanding context, meaning, and intent — thanks to NLP — it will become even harder for SEOs to ‘game’ search.
Good news for content creators that deliver value and content humans actually want to read.
Bad news for those looking for a quick SEO shortcut or hack.
Ruth Burr Reedy, in a Whiteboard Friday for Moz, argues that the best way to optimize your content for BERT and NLP is to become a better writer.
Among Reedy’s recommendations:
- Write short, simple sentences
- Only introduce one idea per sentence
- Connect questions to answers
- Break out subtopics with headings
- Format lists with bullets or number
More and more, making content easier for Google to understand (and rank) also has the additional benefit of making content easier for humans to understand.
Final Thoughts
Before Alan Turing’s role in ending World War II by cracking the Nazi’s Enigma code — a feat estimated to have shortened the war by two years, saving up to 14 million lives — became public knowledge, he was probably best known for the Turing Test.
Seventy years before his face adorned the British £50 note, the Turing Test proposed a simple set of rules to evaluate artificial intelligence.
In essence, a computer is asked to play a game — the imitation game — where it pretends to be human.
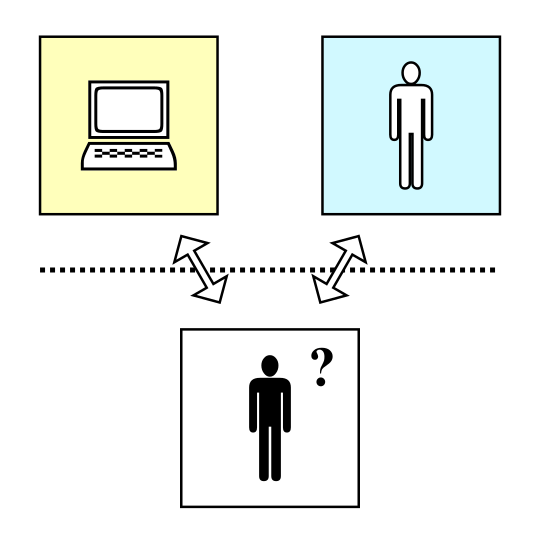 A Turing Test (Source: Almighty Guru)
A Turing Test (Source: Almighty Guru)
{kind=link}
According to Turing, once the machine becomes advanced enough that a human interrogator cannot reliably distinguish the computer’s responses from those of other human beings, the machine has exhibited intelligence.
Despite the staggering advances in computing technology — and NLP — over the last 70 years, no computer has consistently passed the Turing Test.
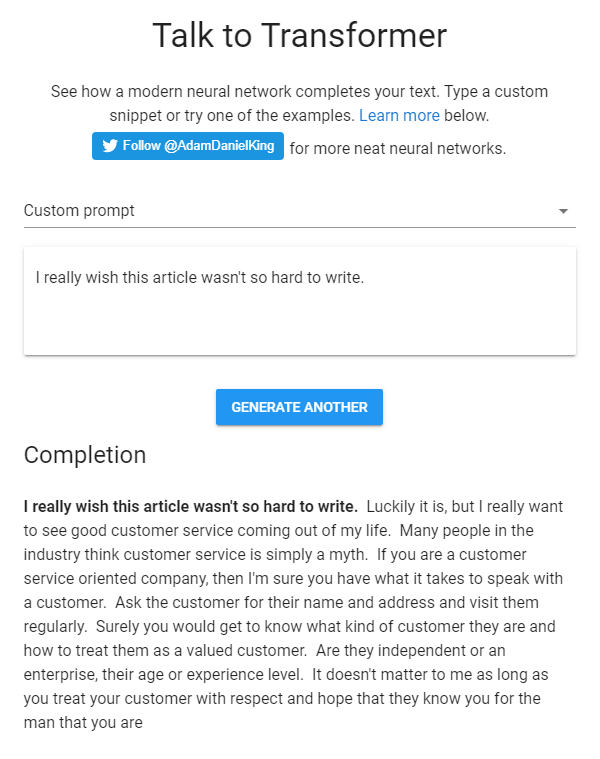 Content Generated by OpenAI’s GPT-2 (Source: Talk to Transformer)
Content Generated by OpenAI’s GPT-2 (Source: Talk to Transformer)
But as recent advances like OpenAI’s text-generating AI system GPT-2 have shown, the day that a machine can think — or at least speak and write — like a human may come sooner than we think.
[cta]
[author_bio image=”https://seobutler.com/wp-content/uploads/2019/06/Sean-Shuter-Circular-Portrait-1-150×150.jpg” name=”SEAN SHUTER”]SEOButler’s Editor-in-Chief, Sean has been writing about business and culture for a variety of publications, including Entrepreneur and Vogue, for over 20 years. A serial entrepreneur, he has founded and operated businesses on four continents.[/author_bio]